语音合成及其配置
当你打开这个页面并希望使用自己的语音模型的时候
我们默认你已经知道配置文件中的vits、bert_vits2、so-vits对应的是不同的语音合成技术。
如果你分不清,那么就用modelscopeTTS和vits模式,大家的时间都很宝贵。
如何自定义语音合成的角色
如下所示,这里是配置区域,请查看config/settings.yaml,windows使用launcher-bot设置,以免出现格式错误。
语音功能设置:
voicegenerate: modelscopeTTS #语音合成模式
speaker: "东雪莲" #根据你的合成模式设定角色
voiceLangType: "<zh>" #默认语音合成语言类型,可选: <zh> <jp> <en>
prefix: "/" #语音合成指令前缀,默认为 xx说 ;如果为 "/" 则指令变为 /xx说 ;用以减少误触发
#下面的两个配置项,除非你自己额外搭了对应的服务,不然就别动。
bert_speakers: #自建bert_vits2语音合成配置,不知道是啥就别动
- rriri #如果搭建了,根据bert_vits_sever/characters.yaml填写所有可用的speakers,没自己搭bert_vits2就别动
so_vits_speakers: #自建so-vits语音合成配置,不知道是啥就别动
- riri #没搭就别动。| voicegenerate(语音合成模式) | 可用speaker | 解释 |
|---|---|---|
| modelscopeTTS | 填写即可,请查看config/语音合成可用角色.txt | 基于modelscope平台,即填即用,默认支持多种语言 |
| outVits | 填写即可,请查看config/语音合成可用角色.txt | 速度很快,可能周期性寄,但角色很多 |
| vits | 取决于装载的模型数量。设置方式如下: 使用指令:@bot 角色 查看所有speaker | 本地vits合成,添加模型请查看,作为数年前的技术,优势在于配置要求低,windows整合包默认装载。 |
| so-vits | so_vits_speakers中选取 | 需自行搭建对应语音合成服务端 |
| bert_vits2 | bert_speakers中选取 | 需自行搭建对应语音合成服务端Bert_Vits2_Sever,但是可以通过modelscope使用从而无需本地搭建。注意,我们的版本是4.0,非此版本训练出的模型无法通过Bert_Vits2_Sever使用 |
vits配置方式
windows整合包默认附带语音模型,以及对应依赖。
其他平台,首先需要进入bot的更新页面,然后选择 安装vits依赖,等待安装完成。这是因为出于体积考量,windows平台之外的整合包已经不再内置vits相关依赖。
导入更多模型(可选)
windows用户导入默认模型
点击launcher/工具页面/一键部署vits模型,重启Manyana,该模型speaker为 薄绿
导入其他模型
在Manyana/vits/voiceModel文件夹下新建一个文件夹,把.pth(模型文件)和config.json(配置文件)放进去
下载模型
已修改配置文件的模型仓库,下载后放在项目对应文件夹下即可。
如何修改触发名?
打开config.json文件。
修改前:"speakers":[{一堆你看不懂的unicode编码}"]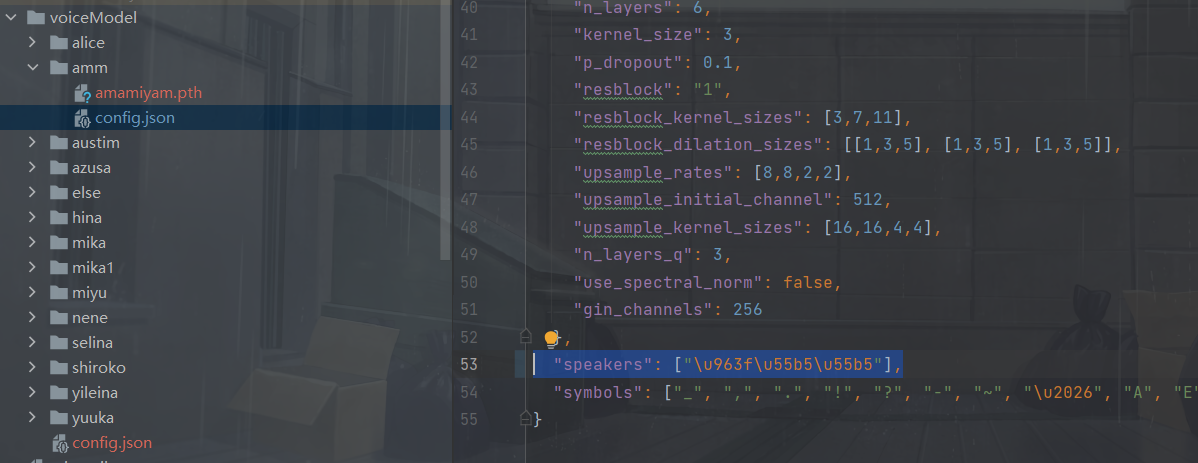
修改后:"speakers": ["薄绿"]